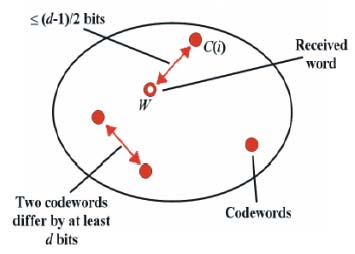
Fig. 1. Graphical interpretation of an error correcting system
A Genetic Algorithm to Design Error Correcting Codes
(c) OPLINK::UNEX. Juan A. Gómez Pulido, 2005
I. Introduction
In some point-to-point communication systems the repetition of a corrupt message is not an objection, but yes in the real time communications, especially in multi-point communications. Thus, in telecommunication systems such as phone, television and digital radio, the information should be delivered with low delay, for which the use of an Error Correcting Code (ECC) is adequate to avoid overloads by transmitting. Many types of ECC exist. In this work we use the binary linear block codes, which are formed by a set of codewords, each of which is a binary string of the same length. The messages are composed by a sequence of codewords. When a message is transmitted, its binary string is sent through the physical environment building a flow of bits that can suffer modifications while crosses it. The error in a codeword is produced when a bit has changed along the way. In the receiver side would arrive an incorrect codeword.
For a given length of the codewords (n) and for a given number of codewords (M), the problem of finding an optimum code that corrects the maximum number of errors is NP-complete. The exact techniques can be useful for small instances, but for more realistic instances they are unfeasible by their high computational cost in time. By this reason, it should be used heuristics such as Genetic Algorithm (GA) [1], Simulated Annealing [2], Parallel Hybrid Heuristics [3], etc. In this work we undertake the problem with a GA.
II. Error Correcting Codes
The error correcting codes are characterized by the following parameters:
Fig. 1. Graphical interpretation of an error correcting system |
A C code can correct up to t errors if d(C) > (2t+1), where, d(C) = min{d(x,y)|x,y |
A binary linear block code can be represented as a vector of three parameters (n, M, d), where n is the number of bits of every word of the code, M is the number of the codewords and d is the minimum Hamming distance between any pair of codewords C(i) and C(j) (i ? j). An optimum code is that one that maximizes d, for a given n and M. In this work we have chosen to solve the instance built for a code of 24 words and 12 bits (M= 24, n= 12) .Then, approximately 10 63 different codes are generated. Therefore, the exhaustive search is clearly discarded.
III. A Genetic Algorithm to Solve the Problem
The GAs imitate the way the nature selects the best individuals. We consider them by several reasons. GAs are used on optimization complex problems whose possible solution set is very high. There are not exact methodologies for finding the optimal solution, where conventional algorithms do not find good results [4][5][6]. The algorithm used, basically consist of an iterative three steps loop (a generation). Each step is characterized by a genetic operator: crossover, selection and mutation, that works (in this order) in each generation.
Representation. It has to be taken into account that the GA requires a good coding in a chromosome. Every chromosome can have several genes, which correspond with the parameters of the problem. To code the solutions of the problem we use a binary string of length M x n. Thus, in this problem each individual (chromosome) of the population is a binary code, represented by means of a M rows and n columns matrix. Every element of the matrix is a binary value (0 or 1) generated randomly.
Fitness function. As fitness function to maximize, we would be able to use the minimum Hamming distance between the codewords. This function is not very useful, because it offers low level of information about the internal advantages of two solutions that compete. A more precise fitness function is the proposal by Dontas and De Jong [1], and shown in (1), where x is the code (vector of codewords) and d ij is the Hamming distance between xi and xj. This function has an objection: it can assign a higher value of fitness to a code with smaller minimum Hamming distance that another. To avoid this problem has been added to the equation a term that enlarges with regard to the minimum Hamming distance. Thus, the final fitness function that we have used is shown in (2), where d min is the minimum Hamming distance between codewords.
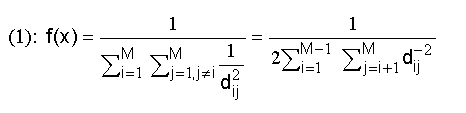
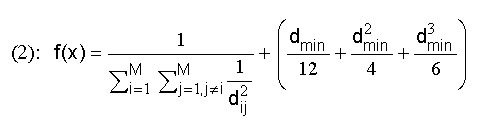
Genetic operators
II. References